pandas学习笔记
1.pandas是什么
Pandas 是 Python 语言的一个扩展程序库,用于数据分析。
Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
Pandas 名字衍生自术语 “panel data”(面板数据)和 “Python data analysis”(Python 数据分析)。
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
2.pandas的应用
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。
3.pandas数据结构
Series 是一种类似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
4.pandas安装
pip install pandas
5.DataFrame
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
data:一组数据(ndarray、series, map, lists, dict 等类型)。
index:索引值,或者可以称为行标签。
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
dtype:数据类型。
copy:拷贝数据,默认为 False。
Pandas DataFrame 是一个二维的数组结构,类似二维数组。
5.1 使用列表创建
1 | import pandas as pd |
5.2 使用 ndarrays 创建
以下实例使用 ndarrays 创建,ndarray 的长度必须相同, 如果传递了 index,则索引的长度应等于数组的长度。如果没有传递索引,则默认情况下,索引将是range(n),其中n是数组长度。
1 | import pandas as pd |
从以上输出结果可以知道, DataFrame 数据类型一个表格,包含 rows(行) 和 columns(列):
5.3 使用字典创建
还可以使用字典(key/value),其中字典的 key 为列名:
1 | import pandas as pd |
6.DataFrame实例
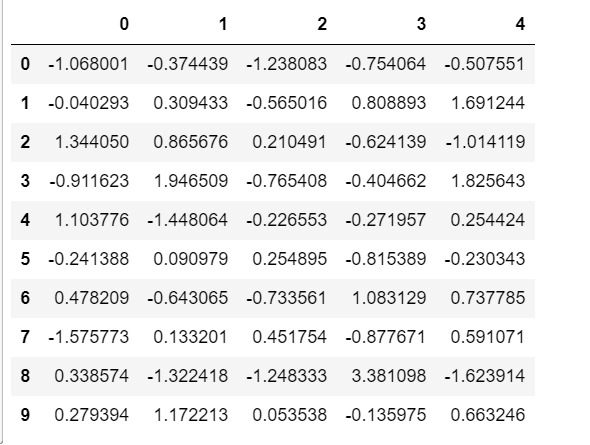
1 | # 创建一个符合正态分布的10个股票5天的涨跌幅数据 |
1 | array([[-1.06800116, -0.37443869, -1.23808272, -0.75406374, -0.50755135], |
1 | import pandas as pd # 导入pandas库 |
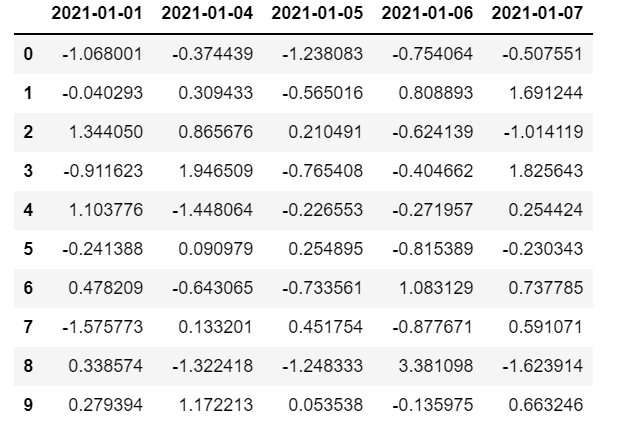
1 | # 添加行索引 |
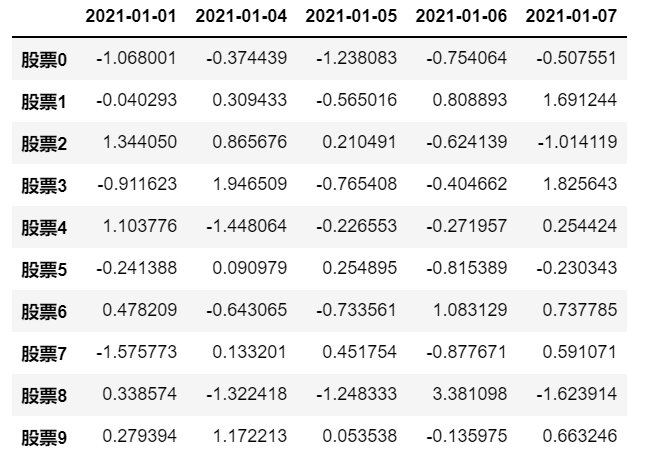
6.1 DataFrame属性
1 | data.shape # 形状 |
6.2 修改行列索引
1 | #不能单独修改某一索引,必须修改整体 |
7.Series
1 | # 带索引的一维数组 只有行索引 |
8.基本的数据结构
1 | data1 = pd.read_csv('stock_day.csv') # 导入文件 |
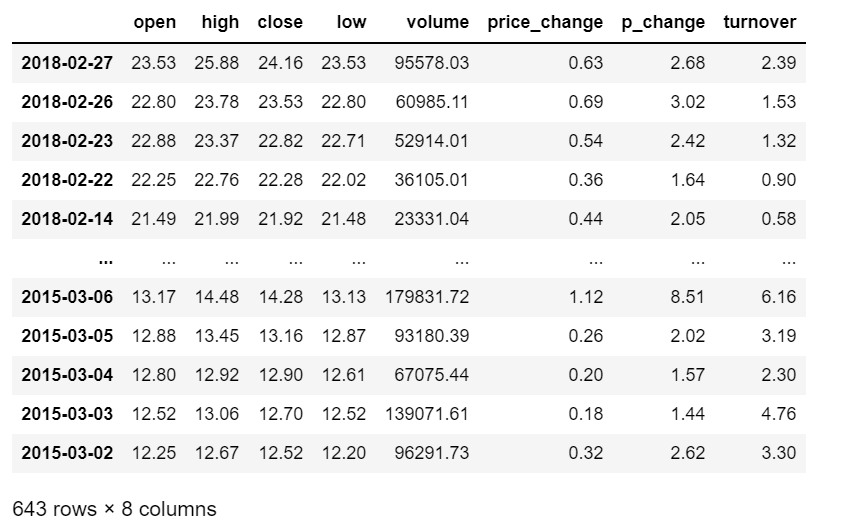
8.1 索引操作
1 | # 直接进行索引(先列后行) |
8.2 赋值操作
1 | # 索引然后赋值 |
8.3 排序
1 | # 1.对内容排序 |
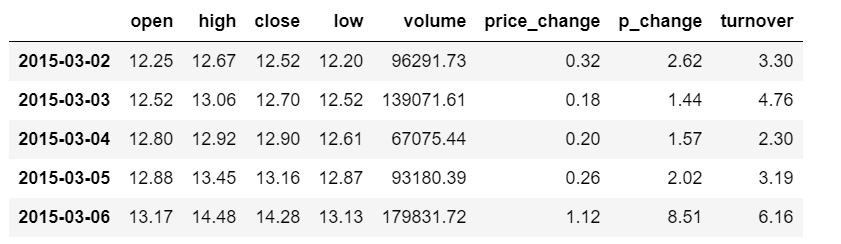
1 | # 用Series进行排序 |
8.4 算术运算
1 | data1['open'] + 3 |
8.5 逻辑运算
1 | # 逻辑运算符 <,>,|,& |
8.6 统计运算
1 | # max,min,mean,median,var,std |
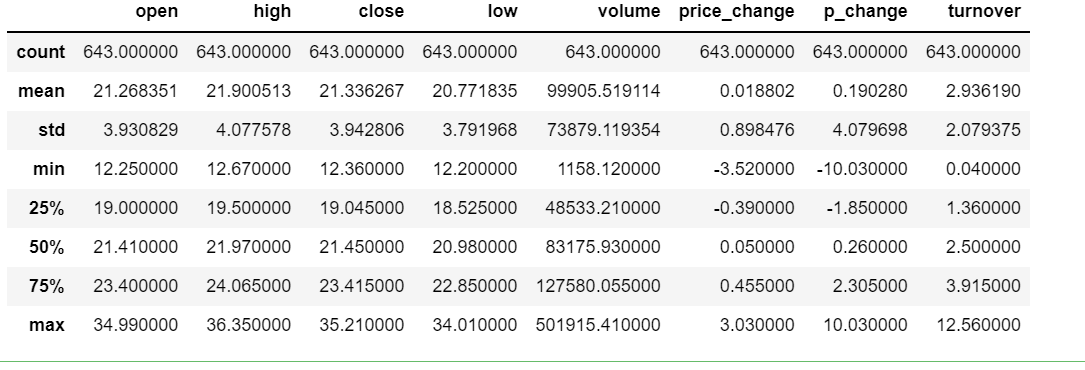
1 | data1.max() # 每列最大值 |
8.7 累计统计函数
1 | # cumsum 累加函数 |
8.8 自定义运算
1 | data1.apply(lambda x:x.max() - x.min()) # 设置最大值—最小值 |
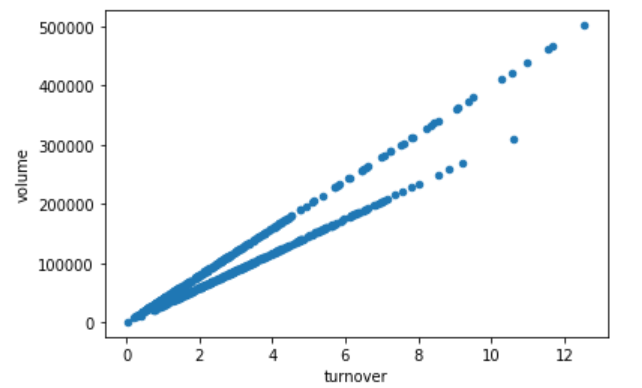
9.pandas画图
1 | data1.plot(x='turnover', y='volume',kind='scatter') # kind为图像类型 |
10.文件的读取与存储
1 | sa = pd.read_json('Sarcasm_Headlines_Dataset.json', orient='records',lines='True') # 读取json文件 |