pandas学习笔记强化
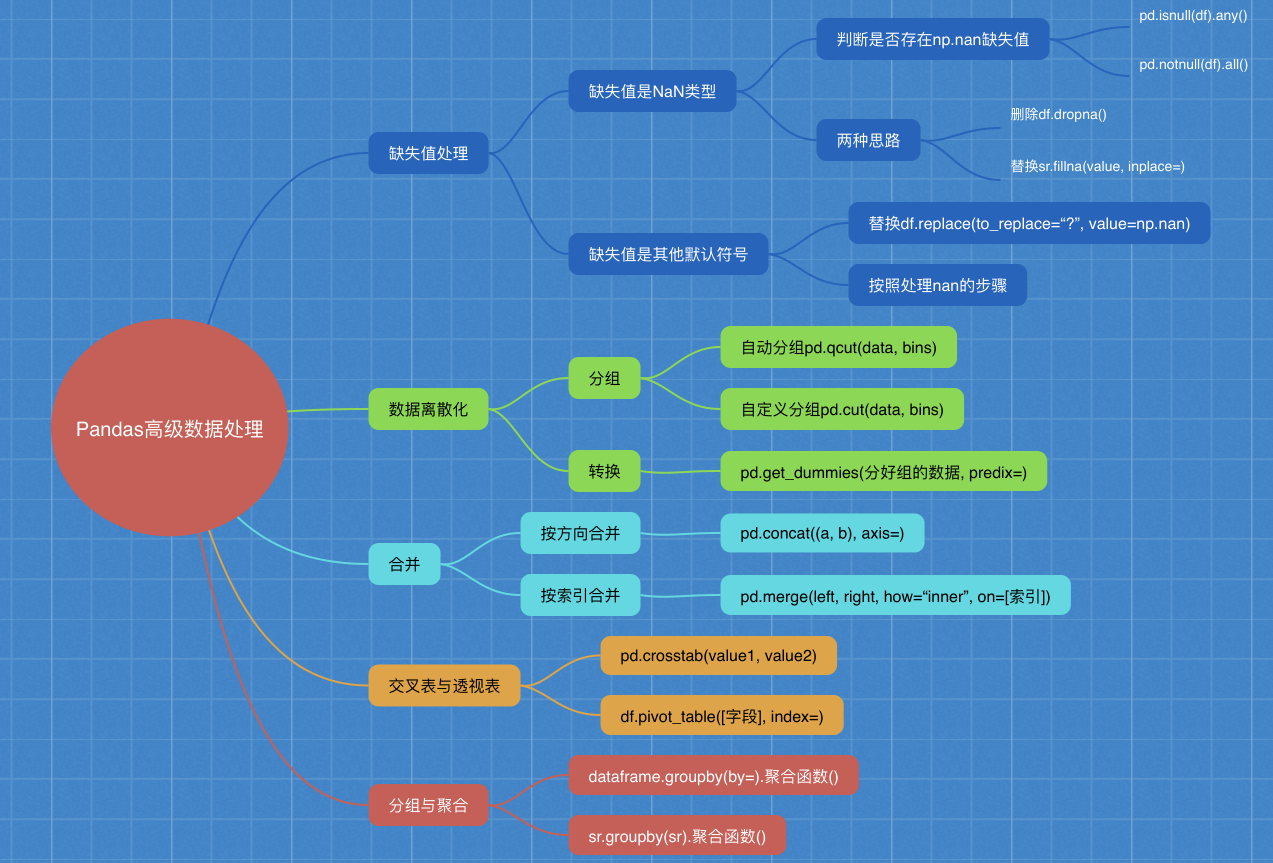
1.如何处理数据中的缺失值
1.1 判断是否存在缺失值
1 | import pandas as pd |
1 | pd.isnull(movie).any() # 返回True,说明数据中存在缺失值 |
1 | pd.notnull(movie).all() # 返回False,说明数据中存在缺失值 |
1.2 缺失值处理
1 | # 2.缺失值处理 |
1 | # 方法2:替换 |

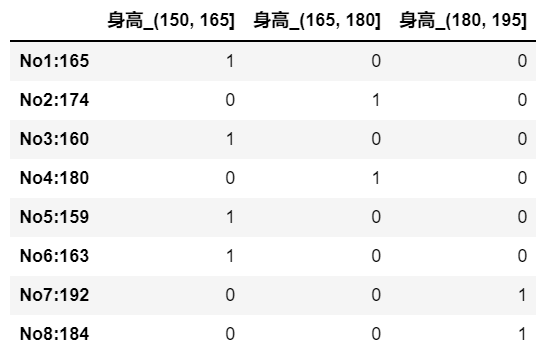
2.如何实现数据的离散化
1 | # 1.准备数据 |
1 | # 3.装换成one-hot编码 |
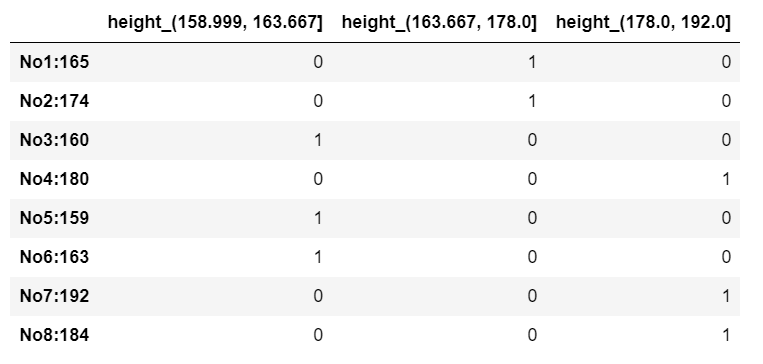
1 | sr.value_counts() # 分组情况 |
1 | # 自定义分组 |
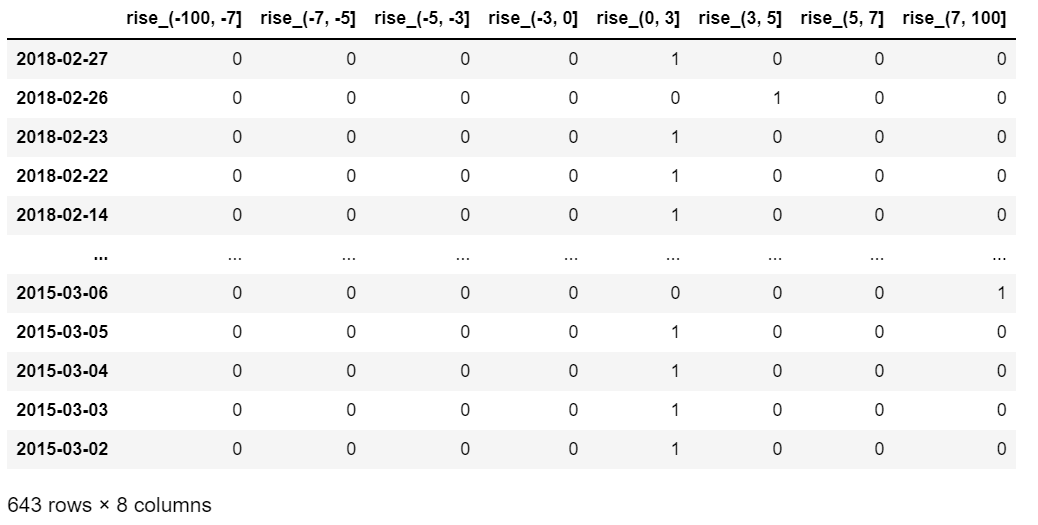
3.案例:股票的涨跌幅离散化
1 | # 1.读取数据 |
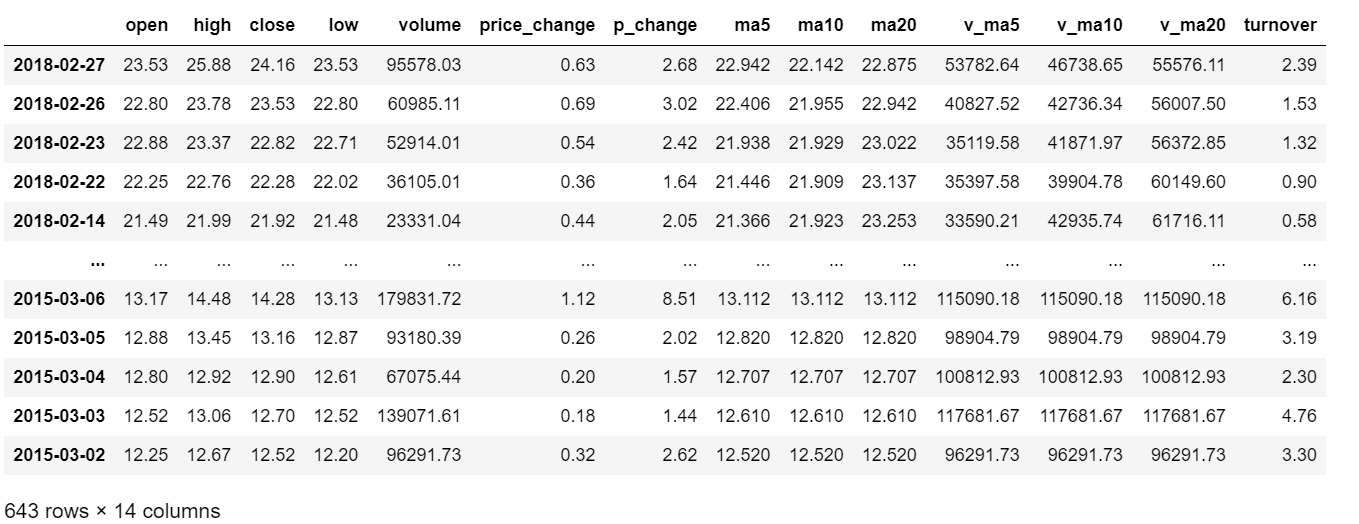
1 | p_change = stock['p_change'] |
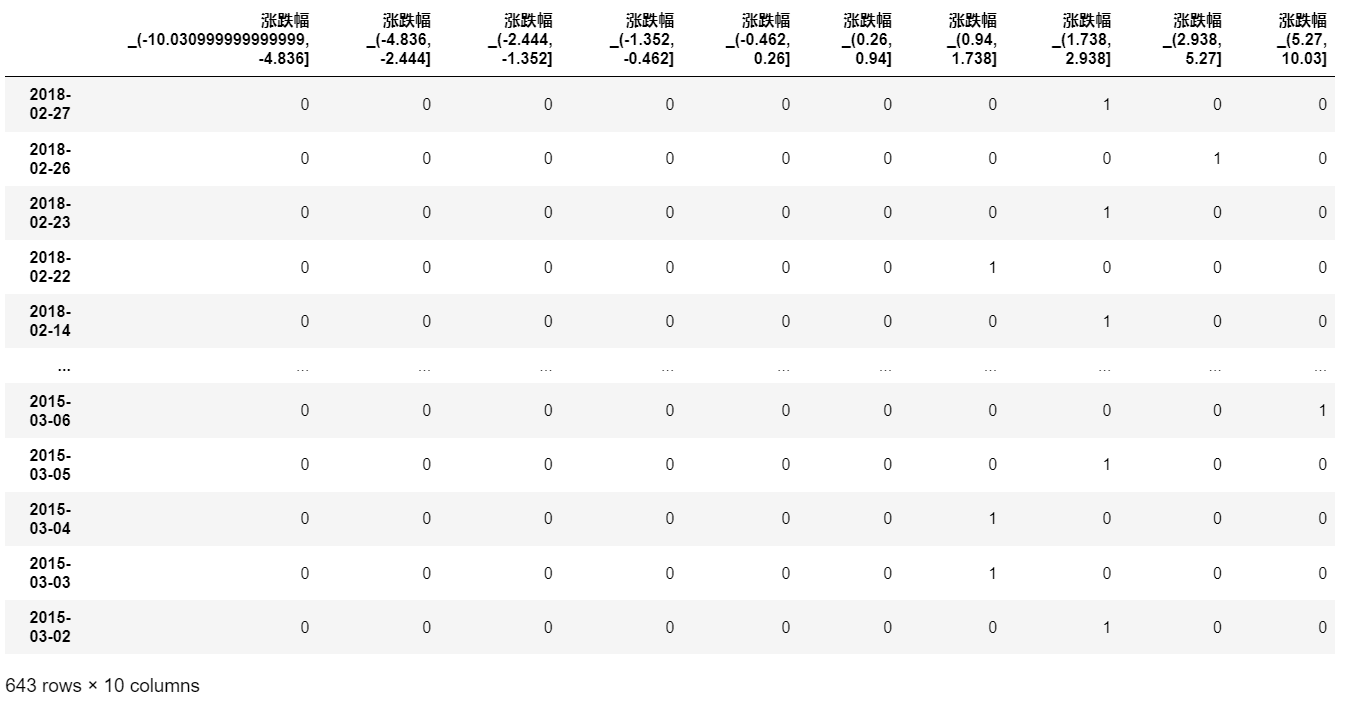
1 | # 自定义分组 cut |
4.pd.concat实现合并
1 | # 进行水平拼接 |
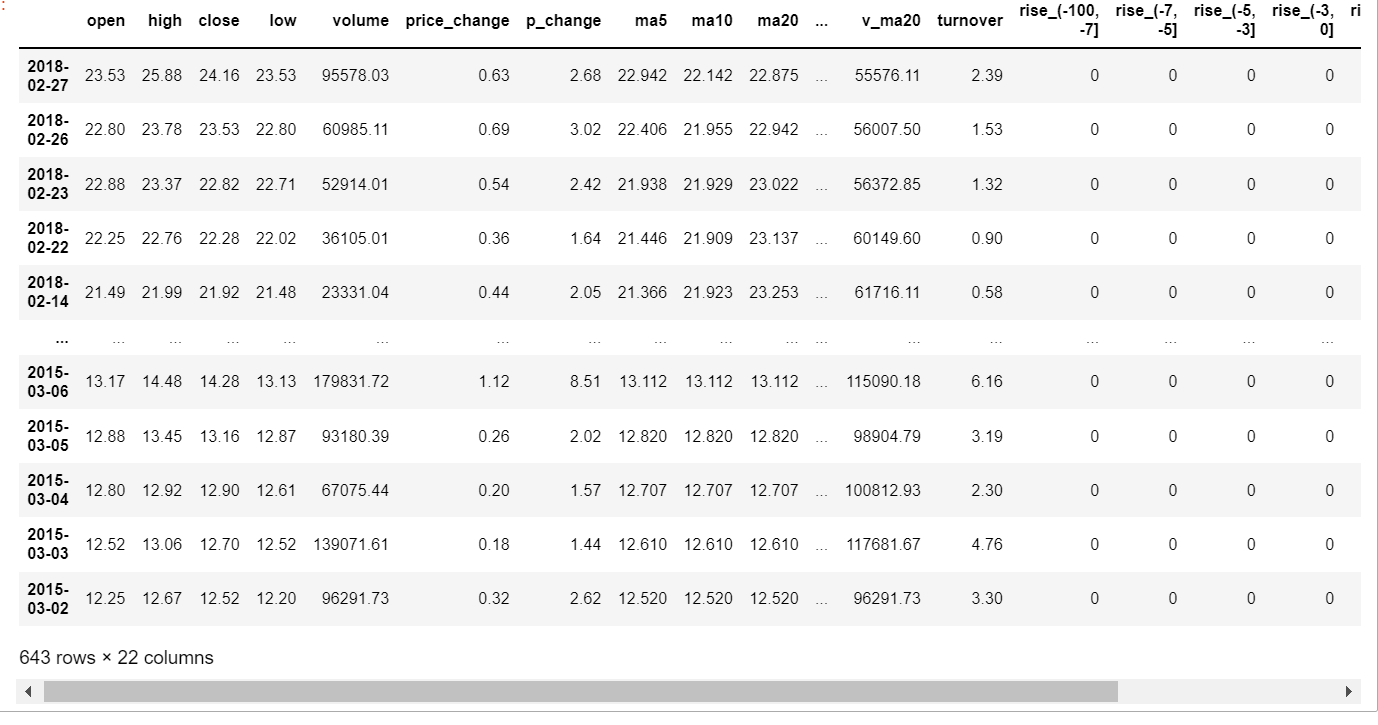
5.pd.merge合并
1 | left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'], |
6.分组与聚合
1 | col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]}) |
7.综合案例
1 | # 1.准备数据 |
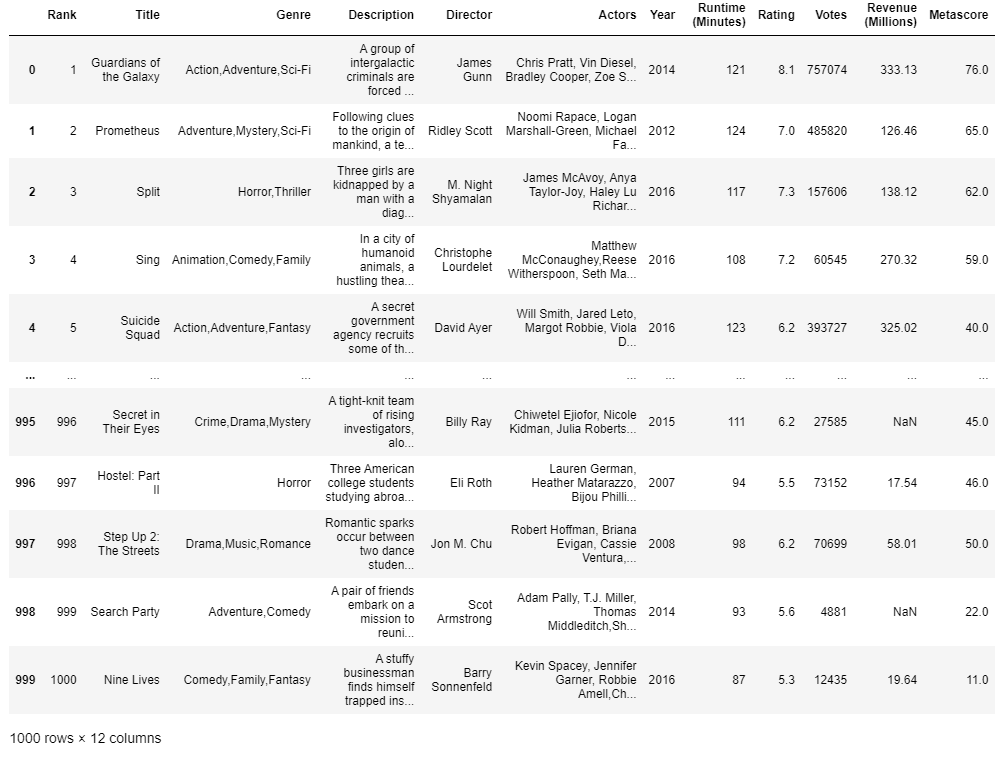
1 | # 问题1:我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取? |
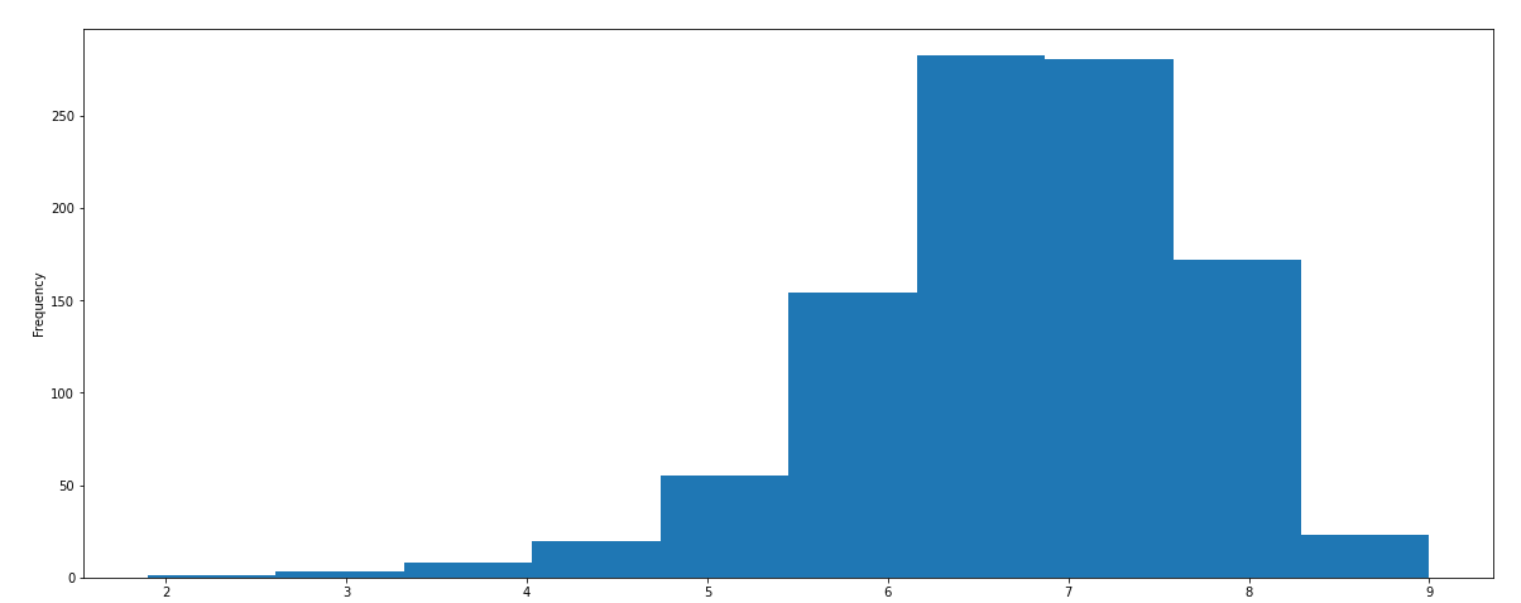
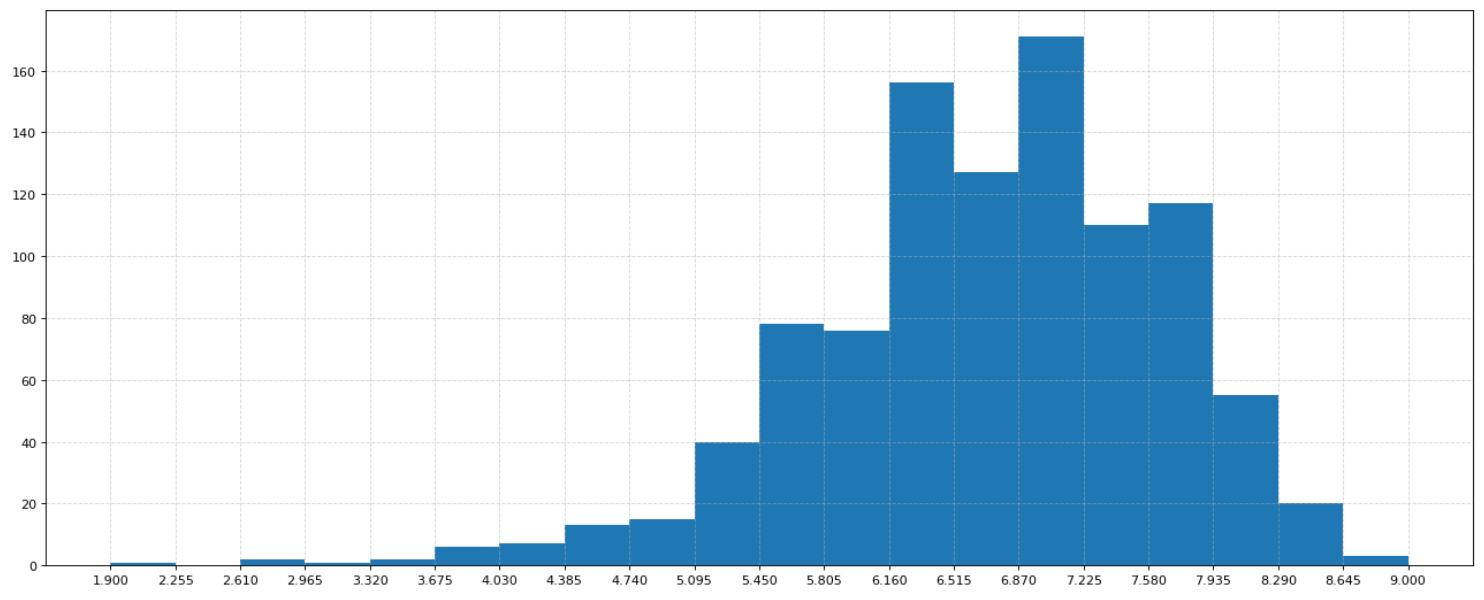
1 | # 利用matplotlib来画 |
1 | # 问题3:对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据? |

1 | movie_class = np.unique([j for i in movie_genre for j in i]) |
8.总结